Placements
Find out how to apply here.
-
Project institution:Project supervisor(s):Dr Thomas Jones (Lancaster) & Archie Dunbar (Lancaster)
Overview and Background

During a volcanic eruption, volcanic ash particles, consisting of fragments of volcanic rock and glass, are ejected into the atmosphere, where they can travel downwind for 100’s of kilometers, posing a significant risk to commercial aircraft and infrastructure. In the event of an eruption, the London VAAC (Volcanic Ash Advisory Centre), hosted at the UK’s Met Office, uses a numerical dispersion model called NAME (Numerical Atmospheric Dispersion Modelling Environment) to produce volcanic ash forecasts. NAME is initialized using numerical weather prediction data and a series of eruption source parameters (ESP’s), that describe the rate volcanic ash is released into the atmosphere, the height of release (plume height) and the ash particle size distribution (PSD). Uncertainty in the ESP’s is a leading cause of uncertainty in the forecasts.
It is not currently possible to directly measure the ash particle size distribution (PSD) during a real eruption, however Costa et al., (2016) showed that the PSD’s of historical eruptions could be fit to some standard, bi-modal distributions whose parameters showed a strong correlation with plume height and the average viscosity of the erupting magma. Thus, in principle, this could be used to estimate the PSD of an eruption in real time, based on plume height measurements and an estimation of magma viscosity.
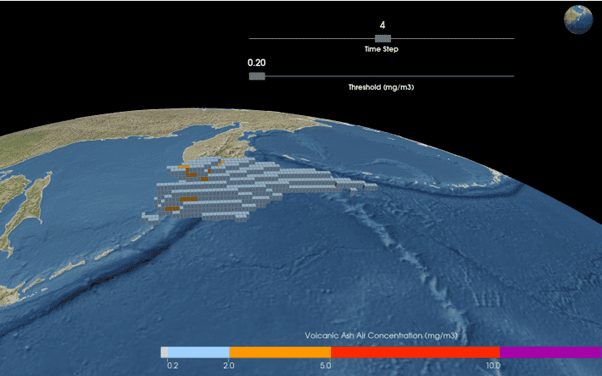
Objectives
You will work within the volcanology research group at Lancaster University and closely with ExaGEO PhD student, Archie Dunbar. They will incorporate new global PSD datasets to improve the fits obtained by Costa et al., (2016). These improved fits will then be used by the student to calculate the PSD for a hypothetical eruption and code a framework to enable this. The calculated PSD will then be used as input for NAME atmospheric dispersion simulations (Jones et al., 2007), with the parameters describing the calculated distribution varied to assess their sensitivity to model outputs.
What you’ll do
- Improve the fits obtained by Costa et al., by incorporating new PSD data sets, including data obtained by Lancaster researchers.
- Use these improved fits to calculate PSD’s for a hypothetical eruption
- Use these PSD’s to perform a sensitivity study with NAME, identifying the key parameters describing the PSD fit that have the greatest impact on output concentrations.
This work will help quantify a key source of uncertainty in volcanic ash forecasts that is currently unknown and will directly contribute to the ExaGEO PhD work of Archie Dunbar.
Why apply
This 10 week placement gives you the chance to work on real volcanic hazard research with direct operational relevance. You’ll gain hands‑on experience with atmospheric modelling, data analysis, and scientific coding, while contributing to work used by the UK Met Office and the wider volcanology community. It’s a rare opportunity to develop valuable skills, work with active researchers, and make a meaningful impact on real‑world forecasting challenges.
References & Further Reading
Costa, A., Pioli, L., Bonadonna, C., 2016. Assessing tephra total grain-size distribution: Insights from field data analysis. Earth Planet. Sci. Lett. 443, 90–107. https://doi.org/10.1016/j.epsl.2016.02.040
Jones, A., Thomson, D., Hort, M., Devenish, B., 2007. The U.K. Met Office’s Next-Generation Atmospheric Dispersion Model, NAME III, in: Borrego, C., Norman, A.-L. (Eds.), Air Pollution Modeling and Its Application XVII. Springer US, Boston, MA, pp. 580–589. https://doi.org/10.1007/978-0-387-68854-1_62
You can find the application form here.
-
Project institution:Project supervisor(s):Professor Adrian Jackson (EPCC)
-
Project institution:Project supervisor(s):Dr Tiffany Vlaar (University of Glasgow)
-
Project institution:Project supervisor(s):Dr Paul R Eizenhöfer & Prof. Kathryn Elmer (University of Glasgow)